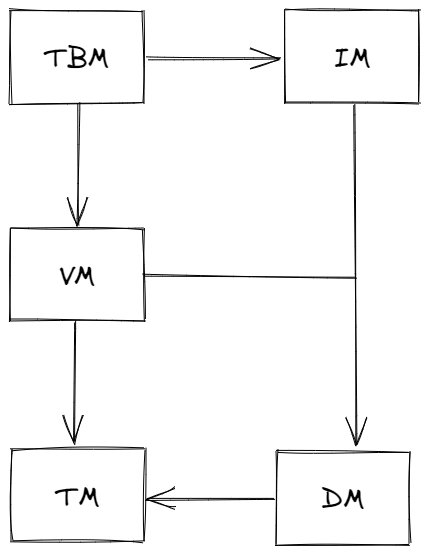
事务管理、数据管理、版本管理、
XID文件:
- TransactionManager 负责维护一个 XID 格式的文件,用于记录各个事务的状态。
- XID 文件中为每个事务分配了一个字节的空间,用来保存其状态。(XID从1开始,XID0默认为未开启事务)
- XID 文件的头部保存了一个 8 字节的数字,记录了这个 XID 文件管理的事务的个数。
DataItemImpl
一个PageCache包含很多个数据页PageX,一个数据页包含多个数据项
数据项,它提供了一种在上层模块和底层数据存储之间进行交互的接口
DataItem 中保存的数据,结构如下:
1 | [ValidFlag]有效位1字节 [DataSize]大小两字节 [Data] |
1 | public class DataItemImpl implements DataItem { |
PageOne
第一页
数据库文件的第一个,用与做一些特殊用途,比如存储一些元数据,用于启动检查等。在MYDB 中的第一页,只是用来做启动检查。
- 每次数据库启动时,会生成一串随机字节,存储在 100~107 字节
- 在正常数据库关闭时,会将这串字节拷贝到第一页的 108~115字节
- 数据库每次启动时,都会检查第一页两处的字节是否相同;用来判断上次是否正常关闭,是否需要进行数据的恢复流程
PageX
普通页,一个普通页面是以 2字节无符号数起始,因为一个页面最大容量为 8k,而二字节的范围是 0到2^16-1,所以2字节作为初始完全足够表达这一页空闲位置的偏移量。页是8KB
1 | * 普通页结构 |
对于普通页的管理,基本上都是围绕着 **FSO(Free Space Offset)**进行管理的;
主要函数
1 | public static byte[] initRaw() { |
日志读写
日志的二进制文件,按照如下的格式进行排布:
1 | [XChecksum][Log1][Log2][Log3]...[LogN][BadTail] |
其中 XChecksum 是一个四字节的整数,是对后续所有日志计算的校验和。Log1 ~ LogN 是常规的日志数据,BadTail 是在数据库崩溃时,没有来得及写完的日志数据,这个 BadTail 不一定存在。
每条日志的格式如下:
1 | [Size][Checksum][Data] |
其中,Size是一个四字节整数,标识了 Data 段的字节数。Checksum 则是该条日志的校验和。Checksum 4字节int
data中为
- Updata为**[LogType] [XID] [UID**(Pageno+offset)] [OldRaw] [NewRaw]
- insert为**[LogType] [XID] [Pgno] [Offset] [Raw]**
UID由页号和页内偏移组成的一个 8 字节无符号整数,页号和偏移各占 4 字节。
recover()
log只有一个日志,根据xid判断是否提交\撤销\活跃,
- 提交\撤销: redo log中的步骤(log正向操作)
- 活跃: undo回滚日志(逆序反操作)
Entry:
VM 并没有提供 Update 操作,对于字段的更新操作由后面的表和字段管理(TBM)实现。所以在 VM 的实现中,一条记录只有一个版本。
一条记录存储在一条 Data Item 中,所以 Entry 中保存一个 DataItem 的引用即可:
一条 Entry 中存储的数据格式如下:
1 | [XMIN]8字节 [XMAX]八字节 [DATA] |
XMIN 是创建该条记录(版本)的事务编号,而 XMAX 则是删除该条记录(版本)的事务编号
data()
相当于是dataitem去掉([ValidFlag]有效位1字节 [DataSize]大小两字节)就是entry的数据格式[XMIN]8字节 [XMAX]八字节 [DATA] ,所以要去掉OF_DATA
1 | // 以拷贝的形式返回内容 |
二叉树索引
基本结构
1 | [LeafFlag][KeyNumber][SiblingUid] |
- [LeafFlag]:标记该节点是否为叶子节点
- [KeyNumber]:该节点中 key 的个数
- [SiblingUid]:是其兄弟节点存储在 DM 中的 UID,用于实现节点的连接
- [SonN] [KeyN]:后续穿插的子节点,最后一个 Key 始终为 MAX_VALUE,以方便查找
table中数据的删除
当上层模块通过 VM 删除某个 Entry,实际的操作是设置其 XMAX。如果不去删除对应索引的话,当后续再次尝试读取该 Entry 时,是可以通过索引寻找到的,但是由于设置了 XMAX,寻找不到合适的版本而返回一个找不到内容的错误。
Booter
MYDB 使用 Booter 类和 bt 文件,来管理 MYDB 的启动信息,虽然现在所需的启动信息,只有一个:头表的 UID
在创建新表时,采用的时头插法,所以每次创建表都需要更新 Booter 文件。
NIO
NIO(New Input/Output)之所以快,主要得益于以下几个关键特性:
1. 非阻塞I/O
- 核心概念:NIO中的
Selector允许一个线程同时管理多个Channel(通道),这些通道可以是文件、套接字等。线程通过Selector监听多个通道的I/O事件(如读、写、连接等),而无需为每个通道单独创建一个线程。 - 性能提升:这种机制减少了线程的阻塞时间。线程不再需要等待某个I/O操作完成,而是可以继续处理其他任务,从而提高了并发处理能力。
2. 直接内存缓冲区
- 核心概念:NIO使用
ByteBuffer等缓冲区来存储数据,这些缓冲区可以是堆内存,也可以是直接内存(Direct Memory)。直接内存位于Java堆外,能够更高效地与操作系统进行数据交换。 - 性能提升:直接内存减少了数据在用户空间和内核空间之间的拷贝次数,从而提高了数据传输的效率。
3. 事件驱动模型
- 核心概念:NIO基于事件驱动模型,允许程序通过
Selector监听多个通道的I/O事件。当某个事件发生时(如数据可读、可写等),Selector会通知程序,程序再进行相应的处理。 - 性能提升:这种模型避免了线程的频繁轮询,减少了不必要的CPU消耗,提高了系统的响应速度。
4. 多路复用
- 核心概念:
Selector能够同时监听多个通道的I/O事件。通过多路复用,一个线程可以同时管理多个连接,而无需为每个连接创建一个线程。 - 性能提升:多路复用减少了线程的创建和切换开销,特别是在处理大量并发连接时,这种机制能够显著提高系统的吞吐量。
5. 零拷贝
- 核心概念:NIO支持零拷贝(Zero-Copy)技术,允许数据在传输过程中直接从源通道传输到目标通道,而无需经过用户空间的缓冲区。
- 性能提升:零拷贝减少了数据拷贝的次数,从而提高了数据传输的效率。
总结
NIO之所以快,是因为它通过非阻塞I/O、直接内存缓冲区、事件驱动模型、多路复用和零拷贝等机制,减少了线程的阻塞时间、数据拷贝次数和系统调用开销,从而显著提高了I/O操作的效率和系统的并发处理能力。这些特性使得NIO在处理大量并发连接和数据传输时具有显著的性能优势。