自制项目
- 用户表(User)
- 字段:用户ID、用户名、密码(加密存储)、邮箱、手机号、角色(摄影师、企业、审核员等)、注册时间、最后登录时间、状态(正常/禁用)。
- 索引:用户ID(主键)、邮箱(唯一)、手机号(唯一)。
- 图片表(Image)
- 字段:图片ID、标题、描述、作者ID(外键→User)、价格、版权状态(已认证/未认证)、分类ID(外键→Category)、上传时间、下载量、浏览量。
- 索引:图片ID(主键)、作者ID、分类ID。
- 订单表(Order)
- 字段:订单ID、用户ID(外键→User)、图片ID(外键→Image)、订单金额、支付状态(待支付/已支付/已关闭)、创建时间、支付时间、交易流水号。
- 索引:订单ID(主键)、用户ID、图片ID。
4 标签表(tag)
- 作用:存储所有可用标签。
- 字段:
tag_id(主键):标签唯一标识(如BIGINT)。tag_name:标签名称(如VARCHAR(50),唯一约束)
浏览量先放redis incr,定时任务扫描Redis并发送消息到MQ,使用mq同步到mysql
不单独存储水印图片,而是在用户访问时动态生成带水印的图片,并利用 CDN缓存 提升访问速度和降低成本。
系统中解决缓存问题
- 布隆过滤器作为第一道防线:在请求到达缓存之前,先通过布隆过滤器判断请求的键是否存在。如果不存在,则直接返回,避免后续的缓存和数据库查询。
- 旁路缓存策略处理正常请求:对于布隆过滤器放行的请求,使用旁路缓存策略进行处理。先查询缓存,缓存命中则返回结果;缓存未命中则查询数据库,并更新缓存。
- 互斥锁+逻辑过期保护数据库:在缓存更新过程中,使用互斥锁确保同一时间只有一个线程可以更新缓存,并结合逻辑过期机制,避免因缓存失效导致的数据库压力骤增。
解释JWT令牌的设计原理?如何防止令牌伪造或篡改?
JWT令牌的设计原理
JWT(JSON Web Token)是一种紧凑的、基于标准的令牌格式,用于在客户端和服务器之间传递认证信息。它由三部分组成:头部(Header)、有效载荷(Payload)和签名(Signature),这三部分通过点号(
.)分隔。- 头部(Header):描述令牌的类型(通常是JWT)和签名算法(如HMAC、RSA等)。
- 有效载荷(Payload):包含实际需要传递的数据,如用户ID、用户名等信息,通常是一个键值对(JSON格式)。
- 签名(Signature):服务器通过 Payload、Header 和一个密钥(Secret)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成
如何防止令牌伪造或篡改
为了防止JWT令牌被伪造或篡改,可以采取以下措施:
选择合适的签名算法:
- 使用强签名算法,如HMAC SHA256(HS256)或RSA(RS256),避免使用弱算法。
密钥管理:
- 定期轮换密钥,减少密钥泄露的风险。
- 使用安全的存储方式保存密钥,如Java Keystore或AWS KMS,避免将密钥硬编码到代码中。
传输安全:
- 确保所有API请求通过HTTPS协议进行传输,防止令牌在传输过程中被中间人攻击(MITM)截取或篡改。
设置合理的过期时间:
- 在JWT的负载中设置合理的过期时间(如30分钟到1小时),以确保令牌在一定时间后失效。
使用刷新令牌机制:
- 当JWT过期时,通过刷新令牌获取新的JWT,避免用户频繁重新登录。
防止重放攻击:
- 在负载中使用一次性的随机值(Nonce)和时间戳,以防止重放攻击。
避免存储敏感信息:
- 不要在JWT的负载中存储敏感信息,因为JWT的负载是Base64编码的,可能被轻松解码。
通过以上措施,可以有效防止JWT令牌被伪造或篡改,从而确保系统的安全性。
两点建议:
1.建议将 JWT 存放在 localStorage 中,放在 Cookie 中会有 CSRF 风险。
2.请求服务端并携带 JWT 的常见做法是将其放在 HTTP Header 的 Authorization 字段中(Authorization: Bearer Token)。
HTTPS
SSL/TLS:
使用非对称加密,对对称加密的密钥进行加密,保护该密钥不在网络信道中被窃听。这样,通信双方只需要一次非对称加密,交换对称加密的密钥,在之后的信息通信中,使用绝对安全的密钥,对信息进行对称加密,即可保证传输消息的保密性。
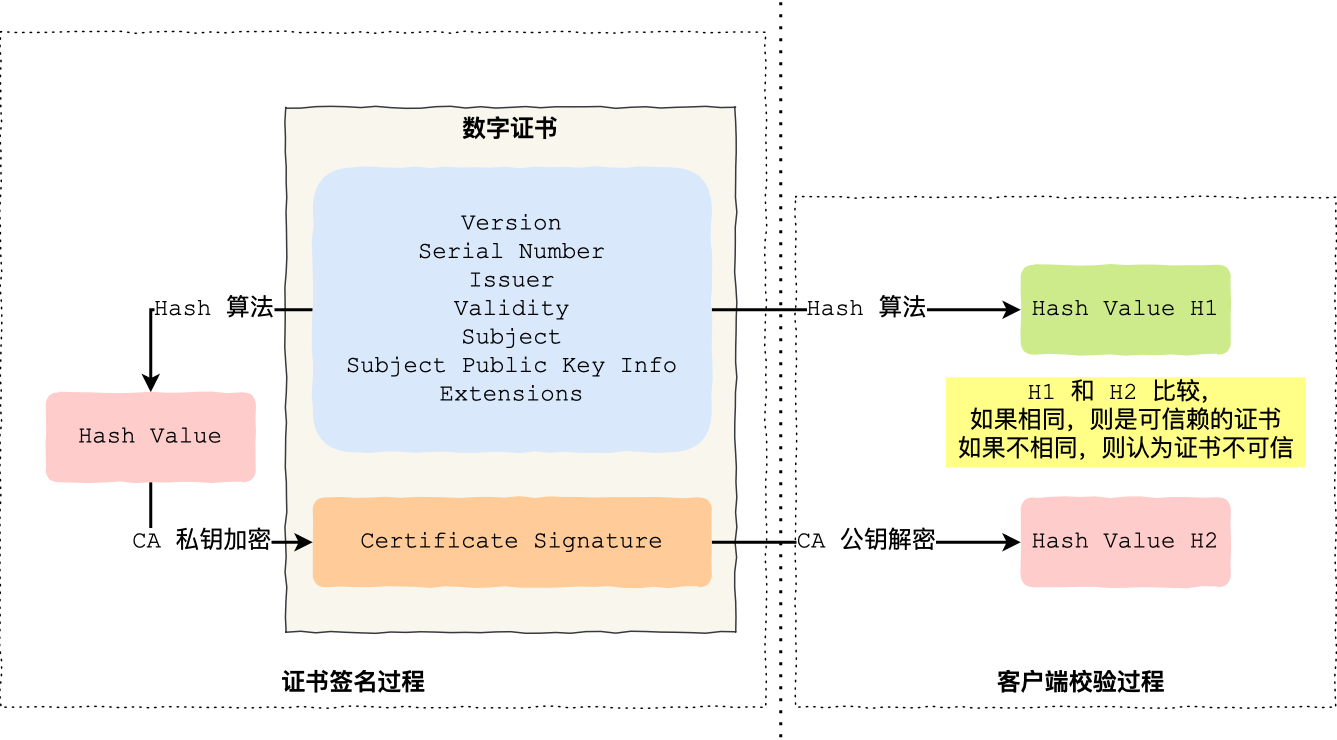
CA给每个服务器发送数字证书(发送者信息和发送者公钥,由CA私钥加密)
现在服务器将该证书发送给客户端,客户端需要验证该证书的身份。客户端找到第三方机构 CA,获知 CA 的公钥,并用 CA 公钥对证书的签名进行解密,获得了 CA 生成的摘要。
客户端对证书数据(发送者信息和发送者公钥)做相同的散列处理,得到摘要,并将该摘要与之前从签名中解码出的摘要做对比,如果相同,则身份验证成功;否则验证失败。
tcp/ip
三次握手,四次挥手




OSS存图片
如果要设计一个图片交易平台,并且图片数据存储在OSS中,同时需要保护图片版权,可以按照以下方案实现:
1. 存储策略
原始图片存储在私有OSS中:将高清原始图片存储在私有Bucket中,确保只有经过授权的用户或系统可以访问,防止未授权的下载或滥用。
有图片样式在其前台展示缩略图,加水印
设计思路
- MySQL存储图片元数据:在MySQL中存储图片的元数据(如图片ID、名称、标签、价格、下载量等),但不存储实际的图片链接。
- Redis缓存图片链接:将OSS生成的带访问时间限制的签名URL存储在Redis中,以图片ID作为键。
- 定期更新缓存链接:通过定时任务定期更新Redis中的签名URL,确保链接始终有效。
2. 访问控制
- 签名URL访问:使用签名URL(预签名URL)访问原始图片,确保只有通过验证的用户可以访问。
- 防盗链配置:设置防盗链规则,限制只有特定来源的网站可以访问图片资源,防止图片被非法引用。
缓存三个问题
缓存雪崩:当大量缓存数据在同一时间过期(失效)时,如果此时有大量的用户请求,都无法在Rdis中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。1.将缓存失效时间随机打散2.设置缓存不过期:
缓存击穿:如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
1.互斥锁方案2.不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
缓存穿透当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
·1.非法请求的限制:因此在AP!入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
·2.设置空值或者默认值:当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
·3.使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
redis三种数据持久化:
1.AOF:
一行一行命令,AOF重写(子进程 bgrewriteaof AOF过大之后重写,)
1.Redis执行完写操作命令后,会将命令追加到server.aof buf缓冲区; 2.然后通过write0系统调用,将aof buf缓冲区的数据写入到AOF文件,比时数据并没有写入到硬
盘,而是拷贝到了内核缓冲区page cache,等待内核将数据写入硬盘; 3.具体内核缓冲区的数据什么时候写入到硬盘(always,everysec,no),由内核决定。
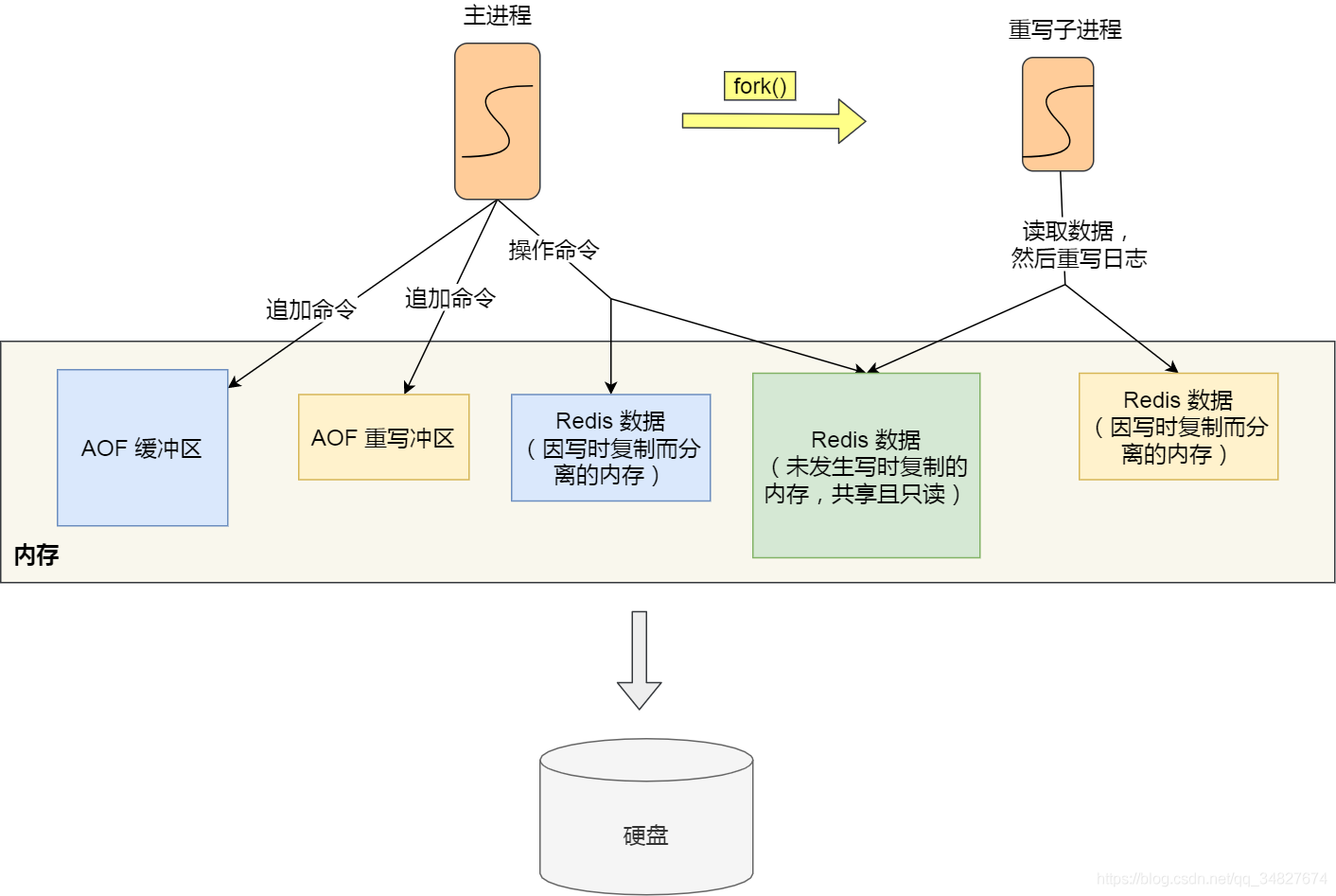
2.RDB
bgsave不阻塞,save阻塞主线程
如果主线程(父进程)要修改共享数据里的某一块数据(比如键值对A)时,就会发生写时复制,于是这块数据的物理内存就会被复制一份(键值对·),然后主线程在这个数据副本(键值对 A’)进行修改操作。与比同时,bgsave子进程可以继续把原来的数据(键值对A)写入到RDB文件。

3.混合持久化工作
在 AOF 日志重写过程。
当开启了混合持久化时,在AOF重写日志时, fork出来的重写子进程会先将与主线程共享的内存数据以RDB方式写入到AOF文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以AOF方式写入到AOF文件,写入完成后通知主进程将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF 文件。
Cache Aside(旁路缓存)策略

不能先删除缓存再更新数据库,
原因是在「读+写」并发的时候,会出现缓存和数据库的数据不一致性的问题。
举个例子,假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。
RabbitMQ
消息队列几种模型
AMQP相较于JMS灵活性更高,有更多的消息模型,:
- direct exchange:直接交换将消息中的 Routing key 与该 Exchange 关联的所有 Binding 中的 Routing key 进行比较,如果相等,则发送到该 Binding 对应的 Queue 中
- fanout exchange:扇出交换是一种将收到的消息路由到绑定到它的所有队列的交换。 当生成者将消息发送到扇出交换时,它会复制消息并路由到绑定到它的所有队列。它只是忽略路由密钥或生产者提供的任何模式匹配。当需要将同一消息存储在一个或多个队列中时,这种类型的交换很有用
- topic exchange:主题交换和直接交换类似,都是通过routing key和binding key进行匹配,不同的是topic exchange可以为routing key设置多重标准
- headers exchange:标头交换用于在多个上路由 更容易表示为消息的属性 标头而不是路由密钥。标头交换忽略 路由密钥属性。相反,用于 路由取自标头属性。一条消息是 如果标头的值等于 绑定时指定的值
- system exchange:系统交换,Publisher向System Exchange发送 routingKey=S 的消息。System Exchange会将该消息转发给名为 S 的系统服务
AMQP统一了消息格式,消息种类只有一种:字节数组(byte[])
消息队列作用
流量削峰。流量削峰是指在请求高峰阶段,将客户端发送的请求添加到消息队列中,然后存储在消息队列中的请求会慢慢发送给数据库,这样能够防止请求一下全部打到数据库上,导致数据库崩溃;
PS:这个类似于缓存,主要目的就是为了降低数据库的压力,防止数据库一下接受到大量请求导致崩溃
应用解耦。应用解耦是指当一个子系统或者子模块出现异常时,并不会影响到整个系统的正常运行,这是因为当某一个子系统出现异常导致某一个请求没有被完成,系统会先将这个出现异常的请求存储到消息队列中,等异常处理完成后,系统再去处理这个因异常而未完成的请求。整个过程用户是完全未感知的,不仅保障了系统的高可用性,还提高了用户的体验
异步处理。异步处理是指发送完请求不需要等待响应结果即可进行下一步操作。以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询;或者 A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务,这两种方式都不是很优雅。使用消息总线,可以很方便解决这个问题, A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此 消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样 B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。
RabbitMQ 延迟队列实现自动关闭超时订单及消息可靠性保障
1. 延迟队列实现自动关闭超时订单
- 使用RabbitMQ延迟插件(rabbitmq-delayed-message-exchange):
- 安装插件:启用RabbitMQ的延迟插件。
- 发送延迟消息:在发送消息时,设置延迟时间,消息会在指定时间后被投递到目标队列。
2. 消息可靠性保障
生产者可靠性:
1.生产者重试
2.生产者确认
1.当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
2.临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
3.持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
4.其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。
MQ可靠性:
- 交换机持久化
- 队列持久化
- 消息持久化
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
- 支持数百万条的消息存储
消费者可靠性:
消费者确认:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
- 如果是业务异常,会自动返回nack;
- 如果是消息处理或校验异常,自动返回reject;
消费者重试:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回reject,消息会被丢弃
**WebSocket **
协议原理
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,支持服务器和客户端之间的双向通信。它通过 HTTP 协议进行初始握手,然后升级为 WebSocket 协议进行数据传输。
长连接管理
长连接管理是确保 WebSocket 连接在长时间内保持活跃和稳定的关键。以下是两种常见的管理机制:
- 心跳机制:
- 作用:防止连接因长时间无数据传输而被断开(如防火墙或代理服务器的超时机制)。
- 实现:
- 客户端和服务器定期发送心跳包(如空帧或特定格式的消息)。
- 如果一方在一定时间内未收到心跳包,认为连接已断开,触发重连。
- 连接池:
- 作用:管理多个 WebSocket 连接,提高资源利用率和系统性能。
- 实现:
- 连接池维护一组可用的 WebSocket 连接。
- 当有新的请求时,从连接池中获取一个连接。
- 使用完毕后,将连接归还到连接池。
- 定期检查连接的健康状态,移除无效连接。
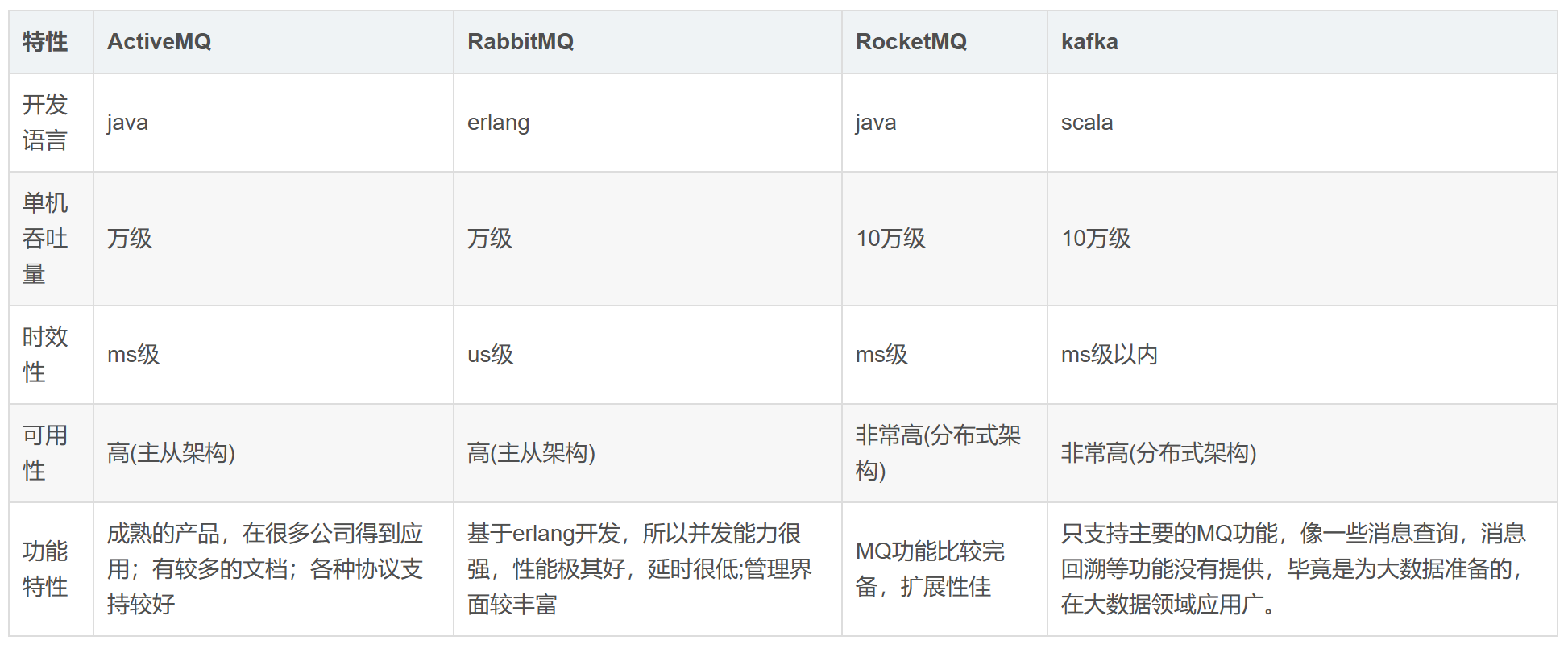
为什么选择RabbitMQ而不是Kafka或RocketMQ?
1. RabbitMQ的优点
- 低延迟:RabbitMQ的延迟非常低,适合对实时性要求较高的场景。
- 功能丰富:支持灵活的路由机制和多种消息模式(如点对点、发布-订阅和主题订阅),满足复杂的应用场景。
- 易用性和可管理性:提供了丰富的API和管理工具(如RabbitMQ Management Plugin),方便监控、管理和配置。
- 社区活跃:拥有庞大的开发者社区和丰富的文档资源,遇到问题时能够得到及时的帮助和支持。
- 支持多种语言:兼容多种编程语言,便于与不同语言的应用程序集成。
2. Kafka的优点
- 高吞吐量:Kafka的设计目标是实现高吞吐量的消息传递,适用于处理大量的实时数据流。
- 扩展性强:采用分布式架构,允许构建高可用性和可伸缩性的消息系统。
- 可靠性:消息持久化到磁盘,支持高效的消息回放。
- 适用于大数据场景:在日志采集、实时计算等大数据领域应用广泛。
3. RocketMQ的优点
- 高吞吐量和低延迟:适合处理大规模数据流,具有高吞吐量和低延迟的特点。
- 可靠性:通过持久化机制和确认机制,保证消息的高可靠性。
- 扩展性:支持水平扩展,可以通过添加更多节点来提高系统性能和容量。
- 功能丰富:支持消息过滤、消息回溯、延迟队列、死信队列等功能。
4. 适用场景
- RabbitMQ:适用于对消息可靠性要求高、需要灵活的消息路由和多种消息模式的场景,如任务队列、发布-订阅和事件驱动架构。
- Kafka:适用于需要高吞吐量、稳定性和可扩展性的场景,尤其是在大数据领域。
- RocketMQ:适用于高吞吐量、低延迟和可靠性要求高的场景,如电商、物流等。
5. 总结
如果您的应用对低延迟和灵活的消息路由有较高要求,RabbitMQ是一个不错的选择。如果您的应用需要处理大规模数据流或在大数据领域有需求,Kafka可能更适合。如果您的应用需要高吞吐量和低延迟,并且对可靠性要求极高,RocketMQ是一个值得考虑的选项。